
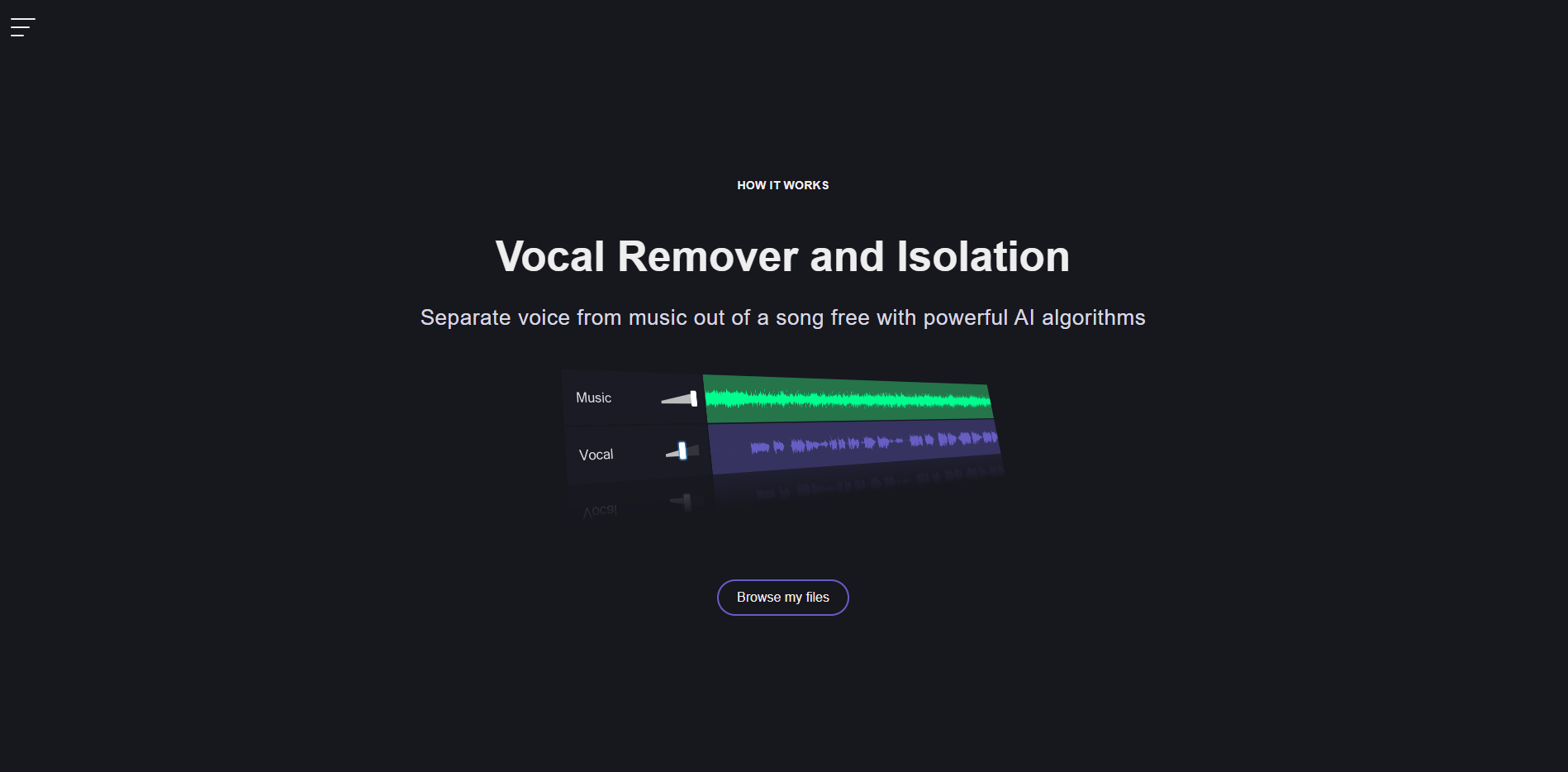
Vocal Remover 是免費線上去除人聲工具,利用 AI 技術將歌曲中的人聲與音樂分離。它還具備錄音、調速、裁切、卡拉 OK等功能。
So-vits-svc (又稱 Sovits) 是基於 VITS、soft-vc、VISinger2 等開發的開源免費 AI 語音轉換模型。
使用者只要輸入人聲樣本,So-vits-svc 模型就會學習及掌握所輸入的人聲的音色和發音特點等,訓練出使用者想要的語音模型。最近不少 AI 翻唱作品就是建基於這個 so-vits-svc 開源項目。
AI 翻唱製作需要訓練模型,不過訓練模型準備工作需時,而且需要不斷測試效果。如果對訓練模型沒有興趣,亦可以使用其他人已訓練好的模型。本篇文章主要是教大家如何使用別人已訓練好的模型,訓練模型教學部份將會在 下一篇文章 (【AI 翻唱 Sovits 4.0 模型訓練教程】如何訓練 AI 翻唱模型) 講解。
準備一首自己喜歡的歌曲,主要是把原始的聲音換成已訓練好的模型聲音。
將歌曲的背景音樂與人聲分離,因為背景音樂會影響模型的推理效果。要將歌曲中的人聲與音樂分離,可以使用線上去除人聲和去除背景音樂工具 - Vocal Remover。
1. 進入 Vocal Remover 網站後,點撃 Browse my files 上傳歌曲。
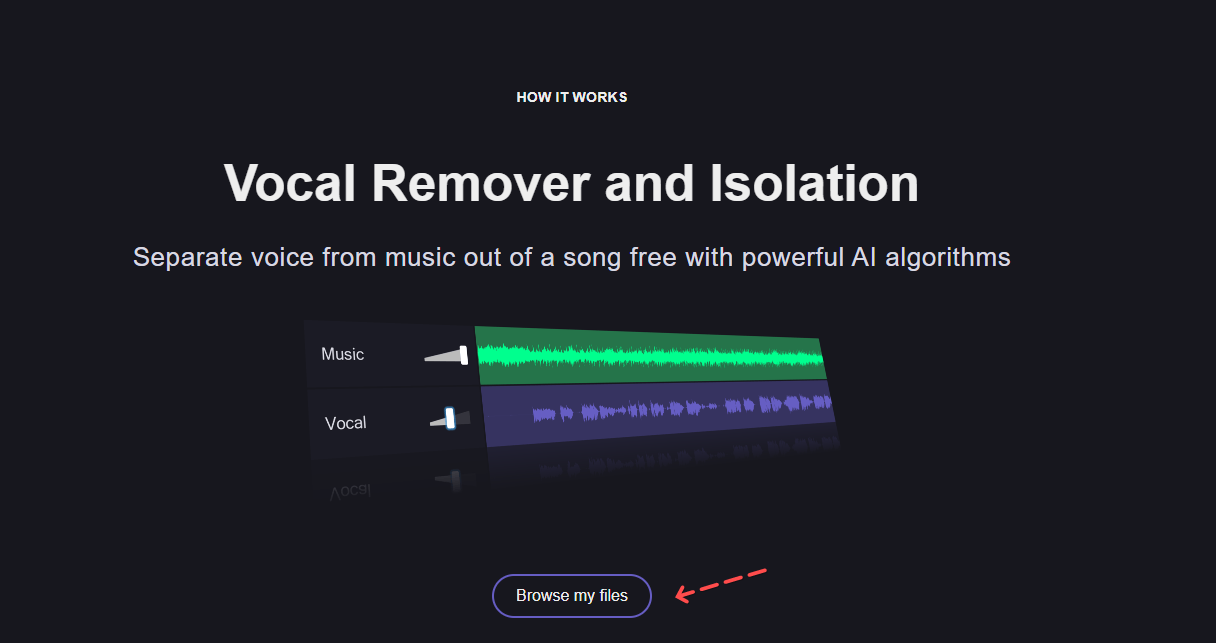
2. 上傳需時 1-2 分鐘,完成後,會見到兩條音軌,上方綠色音軌是音樂,下方紫色音軌是人聲。

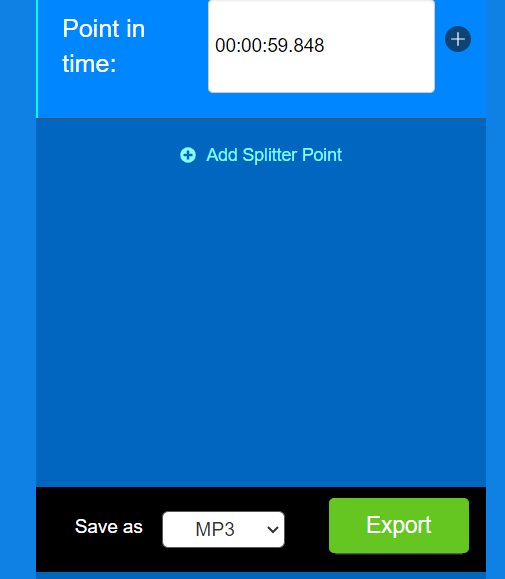
3. 選擇下載 MP3 或 WAV 格式。
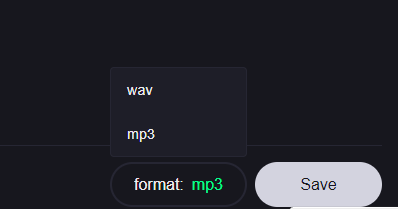
4. 分別選擇人聲及背景音樂,點撃 Save 完成下載 。
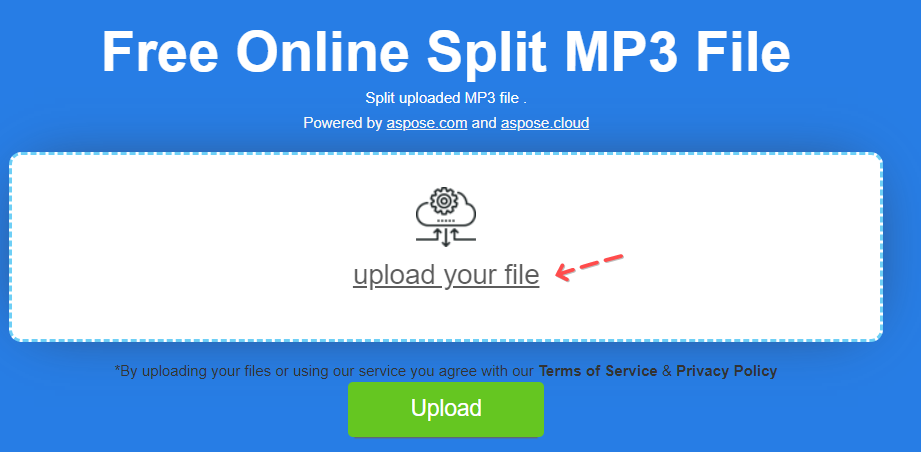
進入 ASPOSE 網站,將人聲分割,大概分為一分鐘一段。
1. 上傳人聲,然後點撃 Upload。
2. 把下方的紅線拉到 1 分鐘位置,然後點撃右側的 "Add Splitter Point" 。
3. 點撃 "Add Splitter Point" 後,會見到下方出現另一條紅線,將紅線拉到 2 分鐘位置,點撃右側的 "Add Splitter Point" 。
4. 如有需要,亦可以收看我的視頻教學: https://youtu.be/79x-1JVbiKQ。
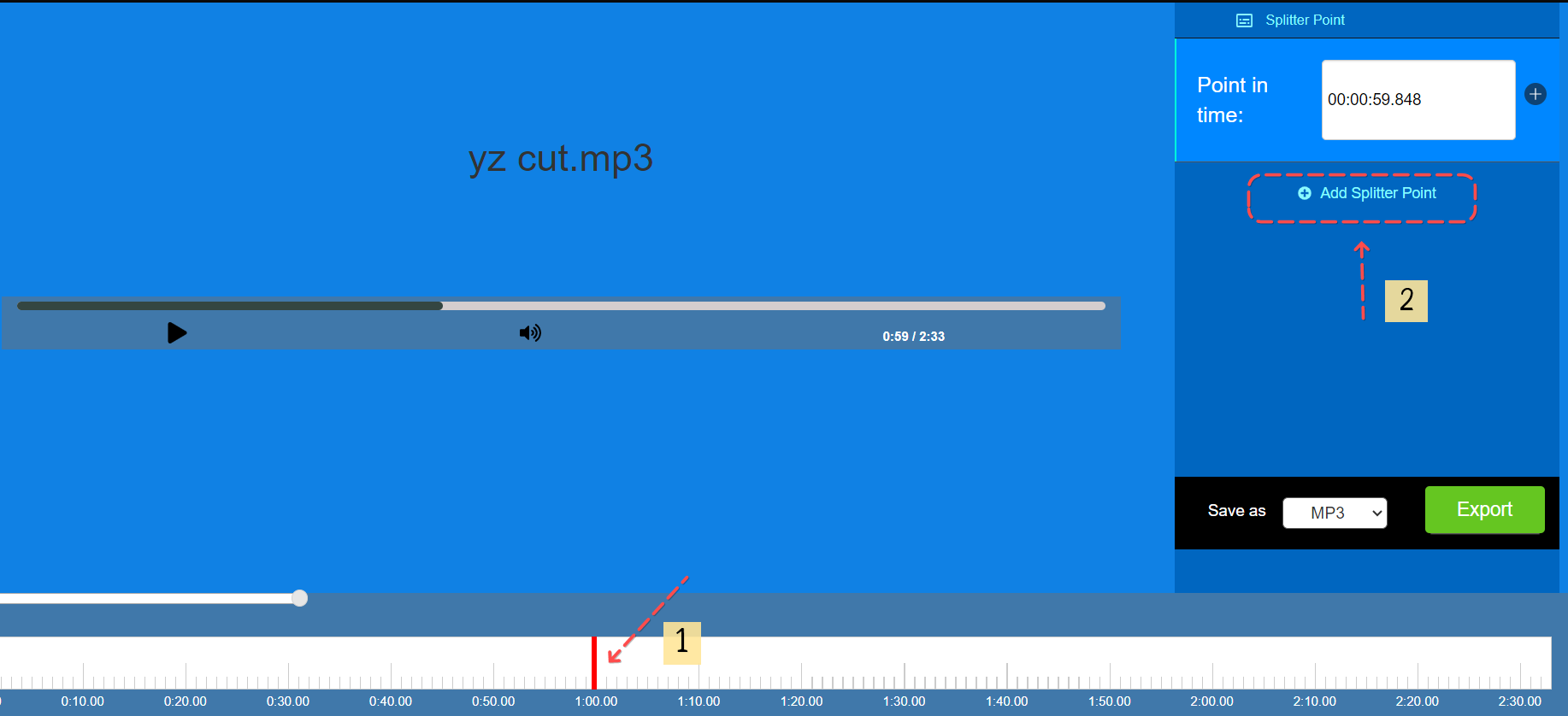
5. 選擇下載格式,然後點撃 Export 完成下載 。
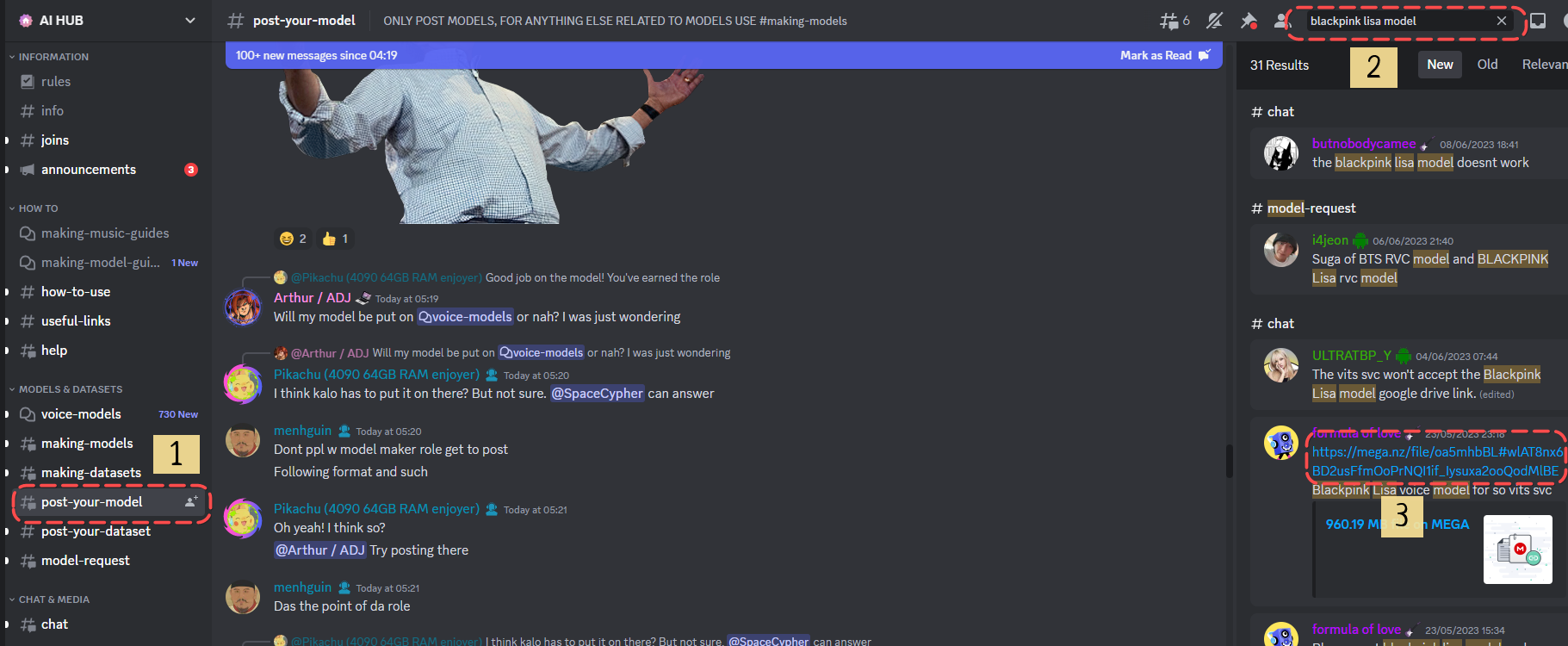
到 AI Hub Discord Channel 尋找模型。
1. 點撃左側 post-your-model。
2. 右上方搜尋模型,以我為例,我搜尋 Blackpink lisa model。
3. 找到 Mega.nz 連結,複製連結備用。
安裝 So-vits-svc 對顯卡規格有一定要求,所以我推薦使用無需安裝的 Google Colab 在雲端訓練。
So-vits-svc Google Colab: 連結
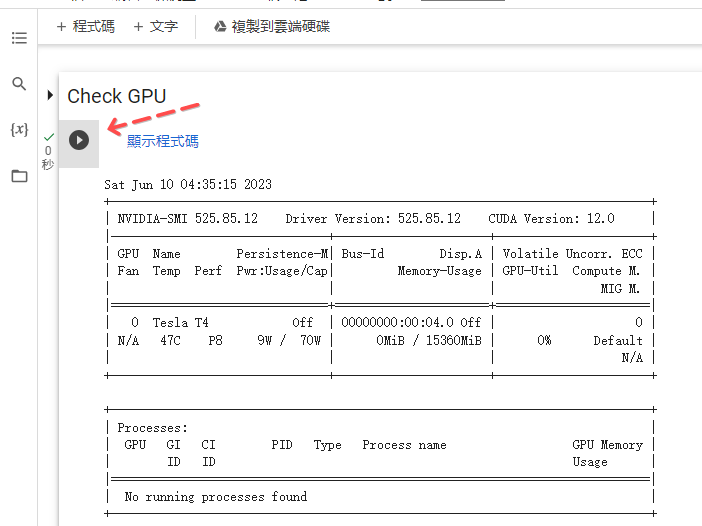
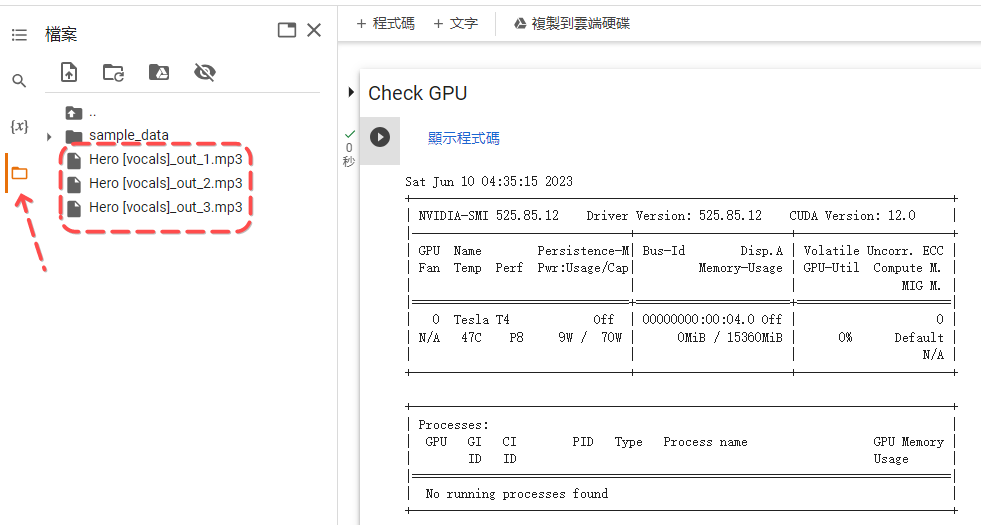
1. Check GPU
2. 點撃左側 Folder,然後上傳已分段的人聲,詳見文章上方分割人聲教學。
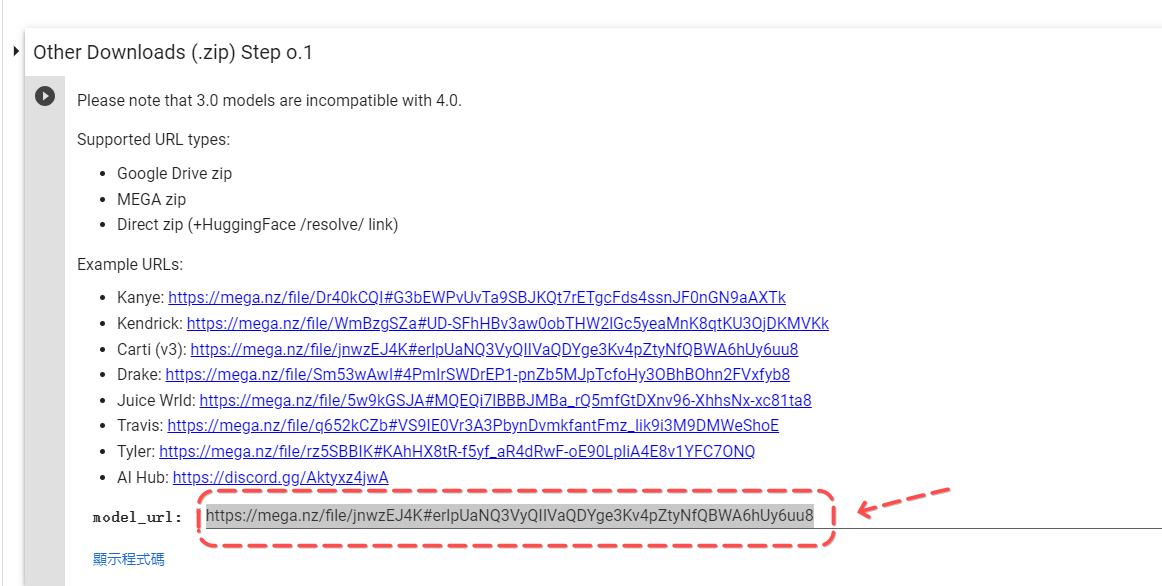
3. 在 model_url 貼上在 AI Hub Discord 已複製的連結。
4. 點撃上方 "執行階段 (Runtime)",然後點撃 "全部執行 (Run All)"。

▋ 相關文章: 【AI 翻唱 (Sovits 4.0模型訓練) 教程】如何訓練 AI 翻唱模型?
👉 推薦 5 個免費好用的文字轉語音 (TTS) AI 工具
👉 Stable Foundation + Gen-2 + ElevenLabs 快速製作動畫
==========================
訂閱 👉 Pulse AI 電子報
✅ 快速掌握最新 AI 工具、科技資訊及品牌應用!
✅ 免費訂閱,節省資料搜集時間!
✅ 加快學習如何運用 AI,減低被淘汰機會!
✅ 每周幾分鐘,工作、學習更高效!
==========================

